The Ultimate OpenClaw Cost Guide: Cut Your Bill from $200 to $10-50 with 10 Config Changes
The Ultimate OpenClaw Cost Guide
Source: https://x.com/lijiuer92/status/2025081922410443243 Author: @lijiuer92 Published: 2026-02-21 Stats: 👍 504 | 🔁 108 | 👁 75,817
OpenClaw is the most capable open-source AI agent out there. But most people's first monthly bill is a shock.
Three things to know upfront:
- 80% of your spend is going to places you don't know about (heartbeat daemon, session bloat, unused skill injection)
- The February 2026 updates (Sonnet 4.6 + 1M Context + nested sub-agents) completely rewrote the cost equation
- These 10 config changes can cut your bill from $200+ to $10-50 — not theory, community-verified results
Skip to Part 6 "The 10-Step Checklist" if you just want the fixes.
Part 1: Where Your Money Actually Goes

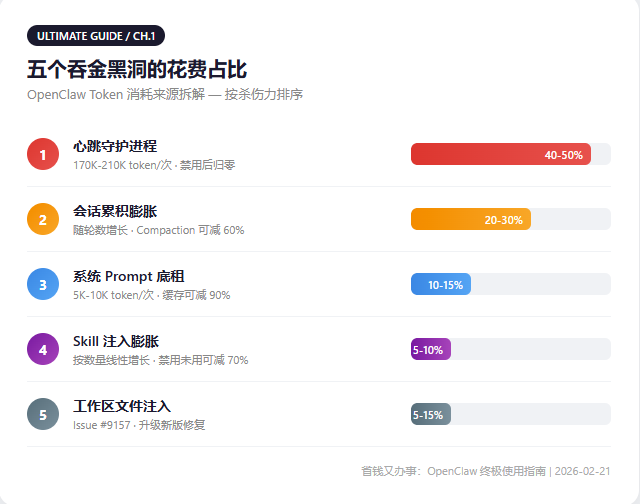
Five money drains, ranked by damage:
🕳️ Drain 1: The Heartbeat Daemon — burning money while you sleep
OpenClaw's Heartbeat Daemon wakes your agent every 30 minutes to check for new tasks. Each heartbeat is a full API call carrying your entire conversation history.
Once your session hits 170K-210K tokens: one heartbeat costs $0.51-$0.63, that's 48 times a day, $720-$900 per month. You're not doing anything. The agent is billing you in the background.
🕳️ Drain 2: Session bloat — the longer you use it, the more each message costs
Round 1: "hello" costs $0.003. Round 50: the same "hello" costs $0.30. That's 100x more expensive.
🕳️ Drain 3: System prompt — the "base rent" on every request
A typical system prompt runs 5,000-10,000 tokens. At 100 interactions per day, that's $67.50/month just in system prompt overhead.
🕳️ Drain 4: Skill injection — installed but unused skills still cost money
Every enabled skill injects 200-400 tokens into the system prompt. Got 18 skills installed but only use 5? Those 13 unused skills waste 3,200 tokens per request.
🕳️ Drain 5: Workspace file injection
GitHub Issue #9157: OpenClaw injects your workspace file list into every message, wasting 93.5% of the token budget in some cases.
Part 2: February Updates You Need to Know
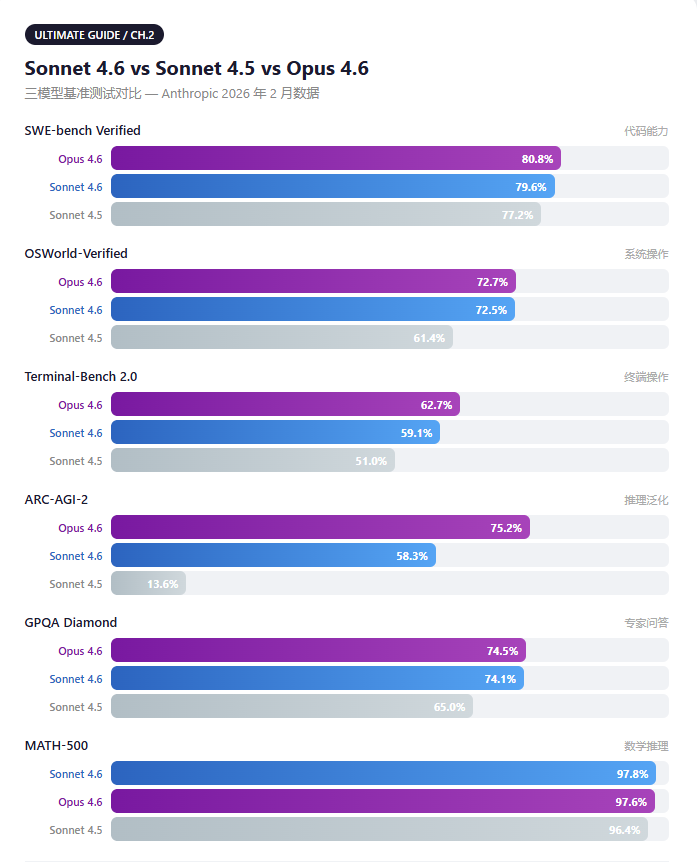
Update 1: Sonnet 4.6 — free upgrade, double the performance
ARC-AGI-2 jumped from 13.6% to 58.3% — a 4.3x improvement. Price: identical to Sonnet 4.5 at $3/$15 per MTok.
User preference tests: Sonnet 4.6 vs Opus 4.5 = 59:41. More than half of users found Sonnet 4.6 comparable to Opus, at 60% of the price.
Update 2: 1M Context — with a cliff
⚠️ The trap: once you cross 200K tokens, all tokens double in price. Going from 199K to 201K doesn't cost you 2K extra tokens — it doubles the price of all 201K. 200K is a cost cliff.
Correct usage: even with 1M available, trigger compaction before hitting 200K.
Update 3: Nested sub-agents
Up to 5 levels deep, theoretically 31 concurrent agent sessions. Each has its own context. Each is billing you. Use cheap models for sub-agents.
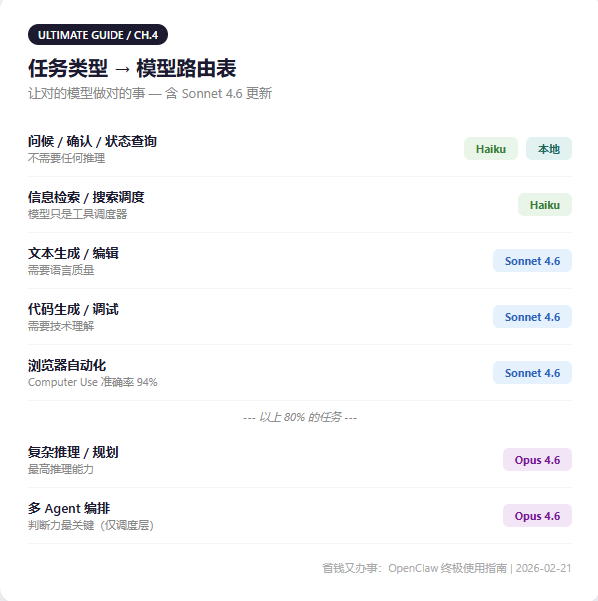
Part 3: Model Routing — Highest ROI Strategy

The Opus-as-Orchestrator pattern:
Opus only plays "general": analyze tasks, make plans, delegate to cheaper models, review results.
Cost comparison (100K tokens/day):
- All Opus: $3.00/day
- Opus orchestration + Sonnet execution: $1.92/day, 36% savings
- Opus orchestration + Haiku execution: $0.84/day, 72% savings
Part 4: Prompt Caching — Free Money

OpenClaw's system prompt runs 5,000-10,000 tokens. About 40-60% of every request is identical repeated content. Anthropic's Prompt Caching gives that portion a 90% discount.
Light usage: 86% savings. Medium: 88%. Heavy: 89%. For high-frequency agents, this is hundreds of dollars.
Part 5: Local Models — Zero API Cost
ollama pull qwen3:32b
OpenClaw natively supports Ollama auto-discovery. Local calls: $0.
Minimum viable quality: 14B+. Community consensus is that 8B models hallucinate too often on tool calls — fatal for agent workflows.
Part 6: The 10-Step Checklist
| Step | Action | Expected Savings |
|---|---|---|
| 1 | Disable heartbeat: agents.defaults.heartbeat.every: "0m" | $150-900/mo |
| 2 | /compact after every task | Varies |
| 3 | Switch default to Sonnet 4.6 | 40% off |
| 4 | Disable unused skills | 200-400 tokens/request/skill |
| 5 | thinkingDefault: "minimal" | 50% reasoning tokens |
| 6 | Enable prompt caching | 86-89% on system prompt |
| 7 | compaction.mode: "safeguard", targetTokens: 50000 | Saves tokens + preserves memory |
| 8 | Model routing: 50% Haiku + 30% Sonnet + 20% Opus | 60-72% off |
| 9 | Add "Be concise" to SOUL.md + max_tokens limit | 30-50% off output |
| 10 | Deploy local model (Ollama) | Cut bill in half |
Part 7: Real Cases
- $150 → $35/mo (77% cut): Disabled 13 unused skills + reset after tasks + prompt caching. Under 1 hour of work.
- $1,200 → $50/mo (96% cut): Full model routing + heartbeat on local + output limits.
- $400/mo, no regrets: Coordinating multiple dev instances from Disneyland via Telegram. "Better ROI than hiring staff."
Quick Config Template
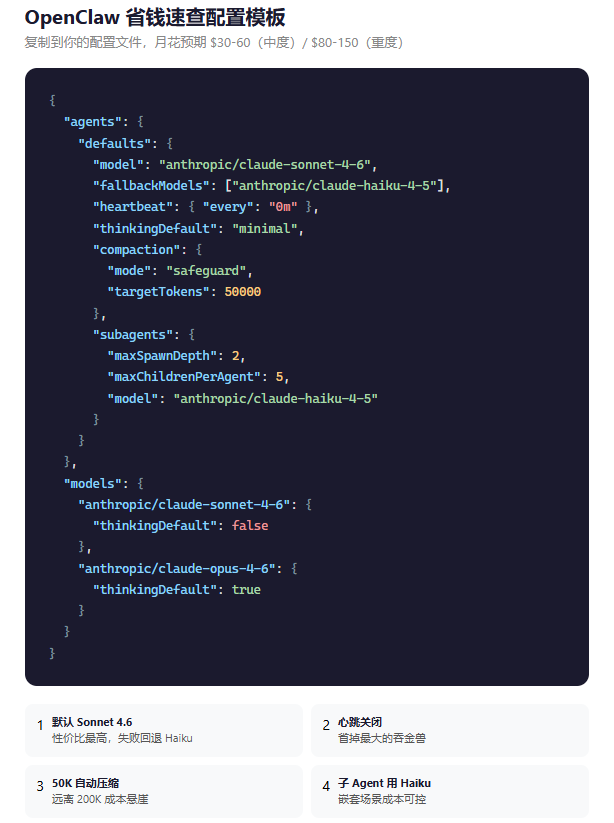
agents:
defaults:
model: "anthropic/claude-sonnet-4-6"
fallbackModel: "anthropic/claude-haiku-4-5"
heartbeat:
every: "0m"
thinking:
default: "minimal"
compaction:
mode: "safeguard"
targetTokens: 50000
subAgents:
model: "anthropic/claude-haiku-4-5"
thinking:
sonnet: false
opus: true
Expected monthly spend: moderate usage $30-60, heavy usage $80-150.
Original: https://x.com/lijiuer92/status/2025081922410443243 | via @lijiuer92